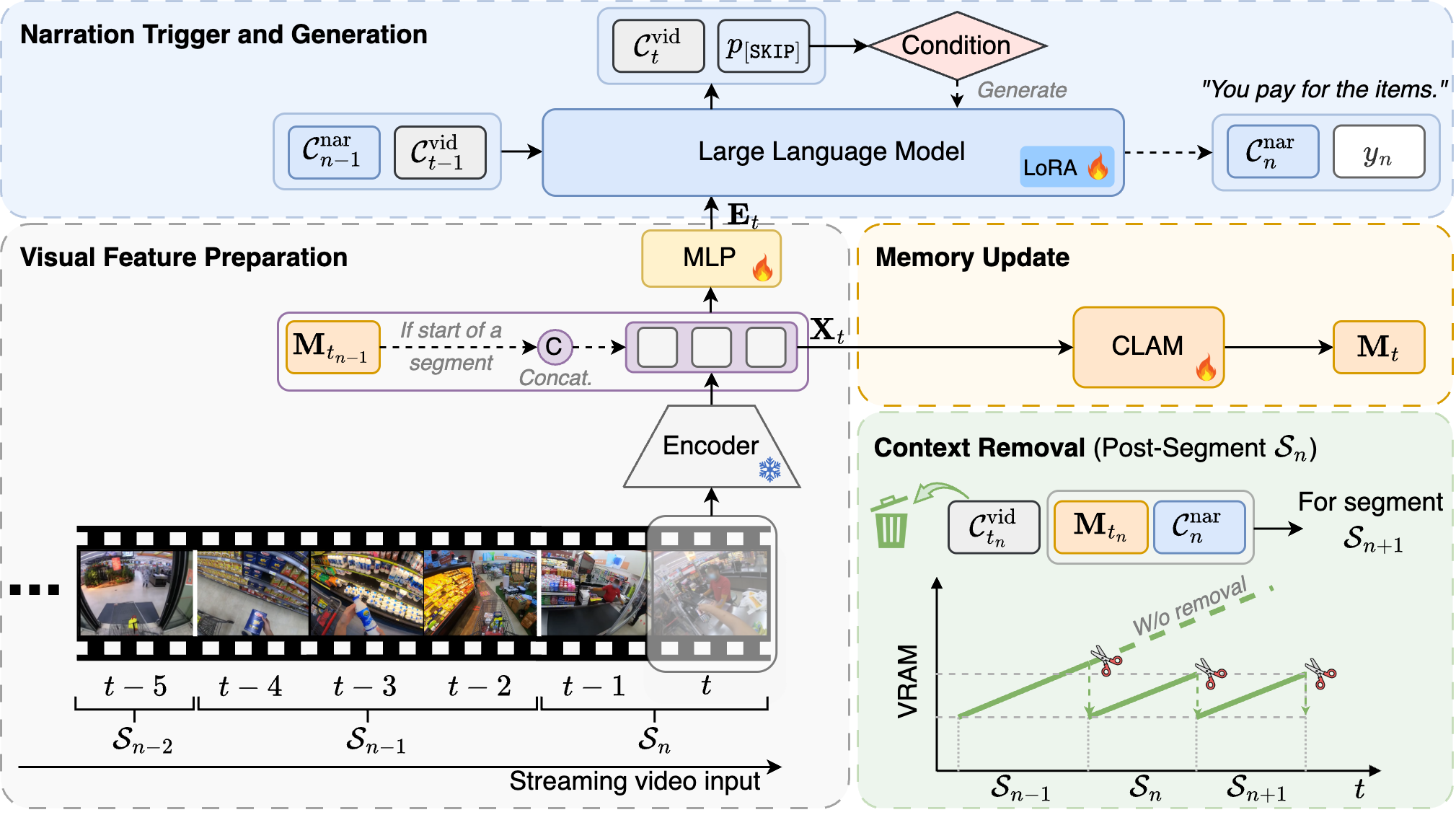
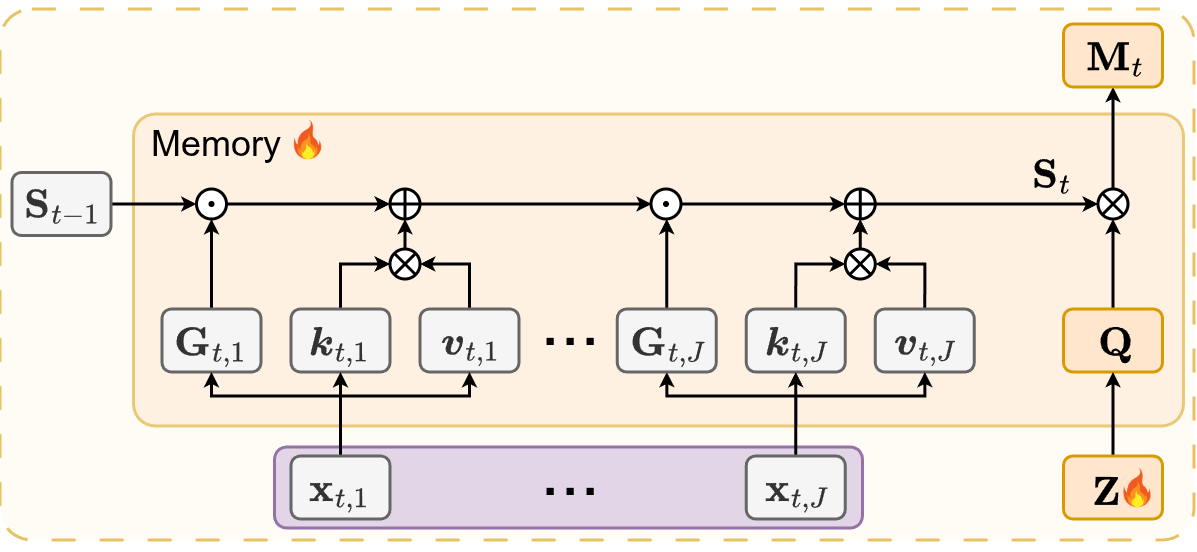
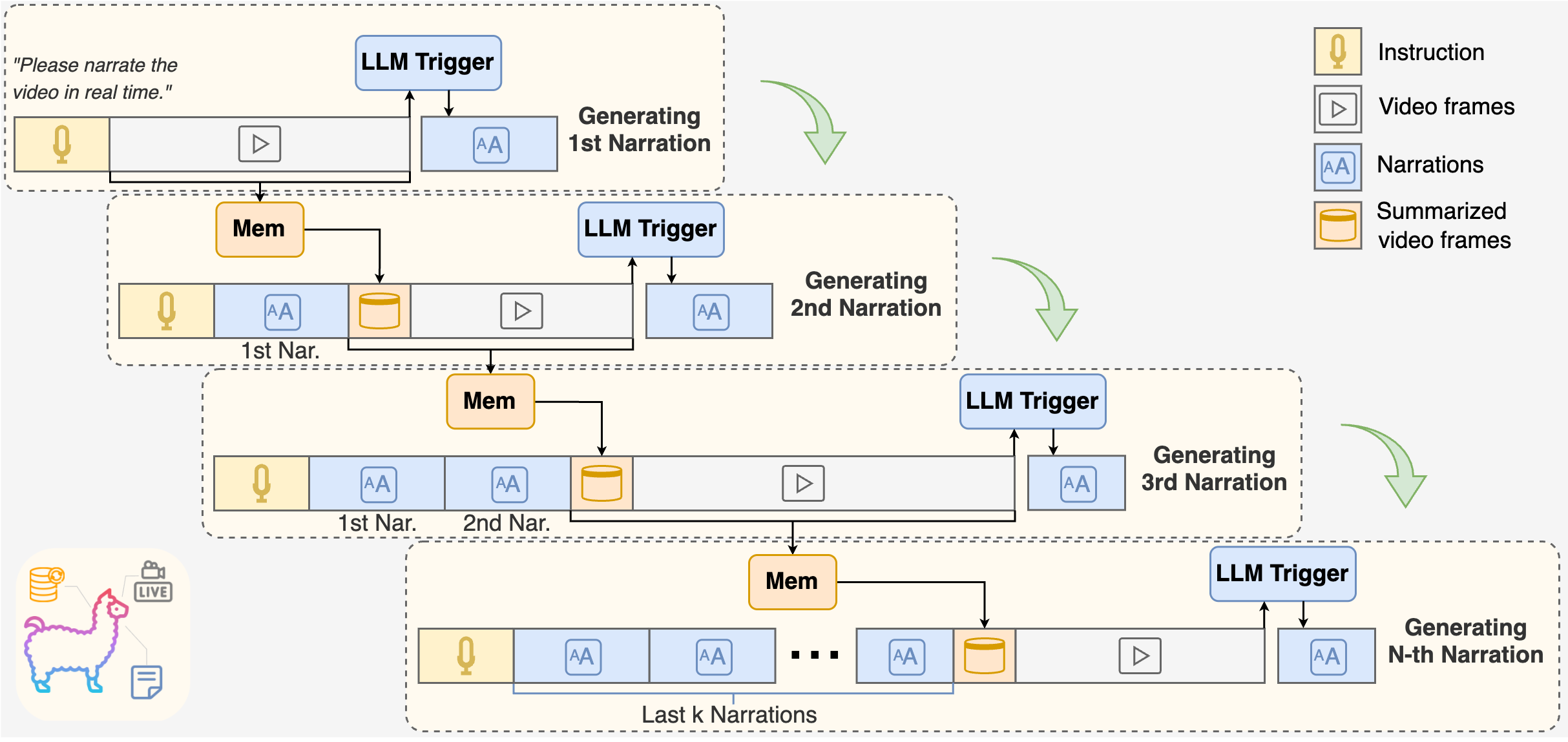
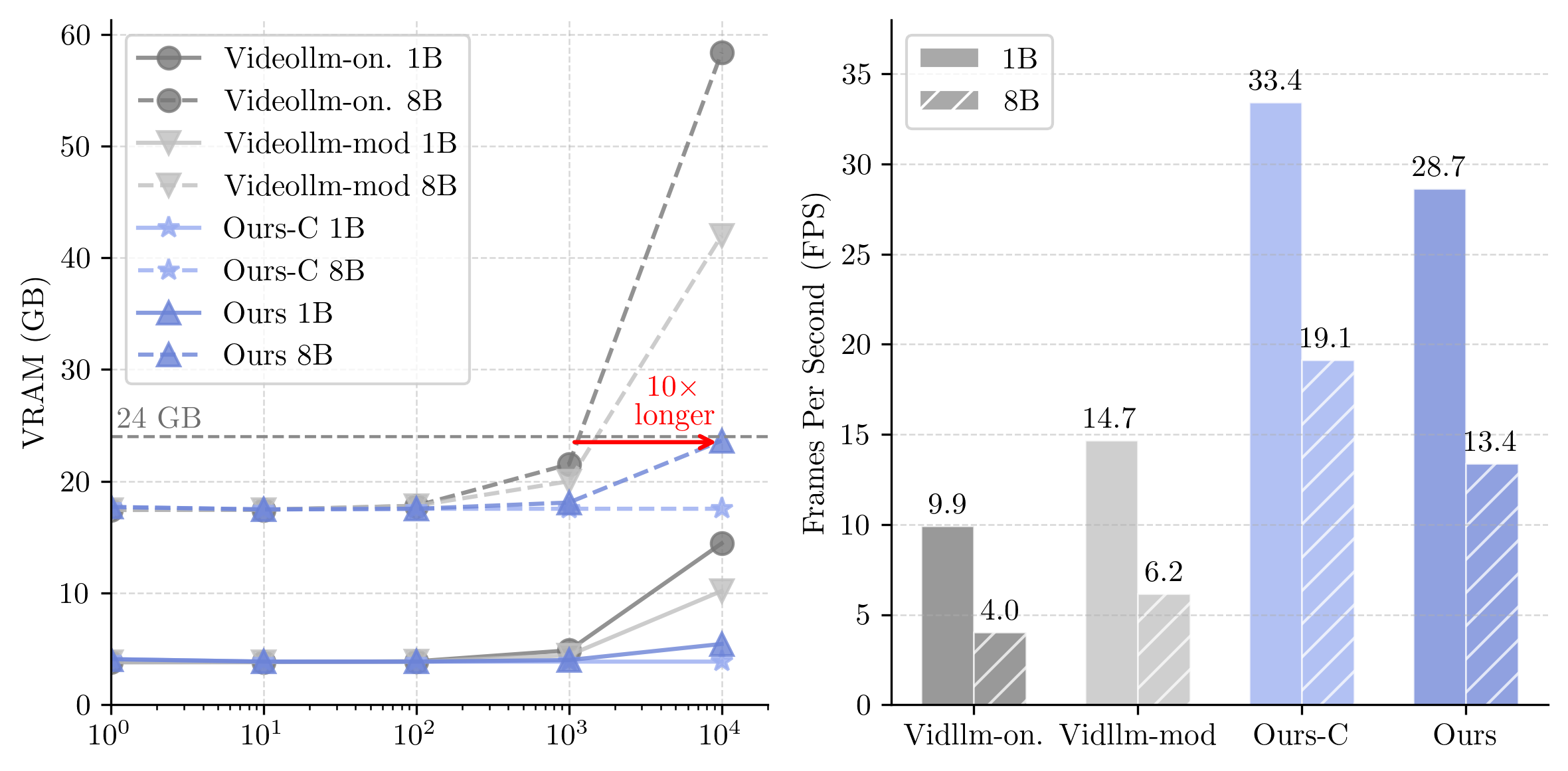
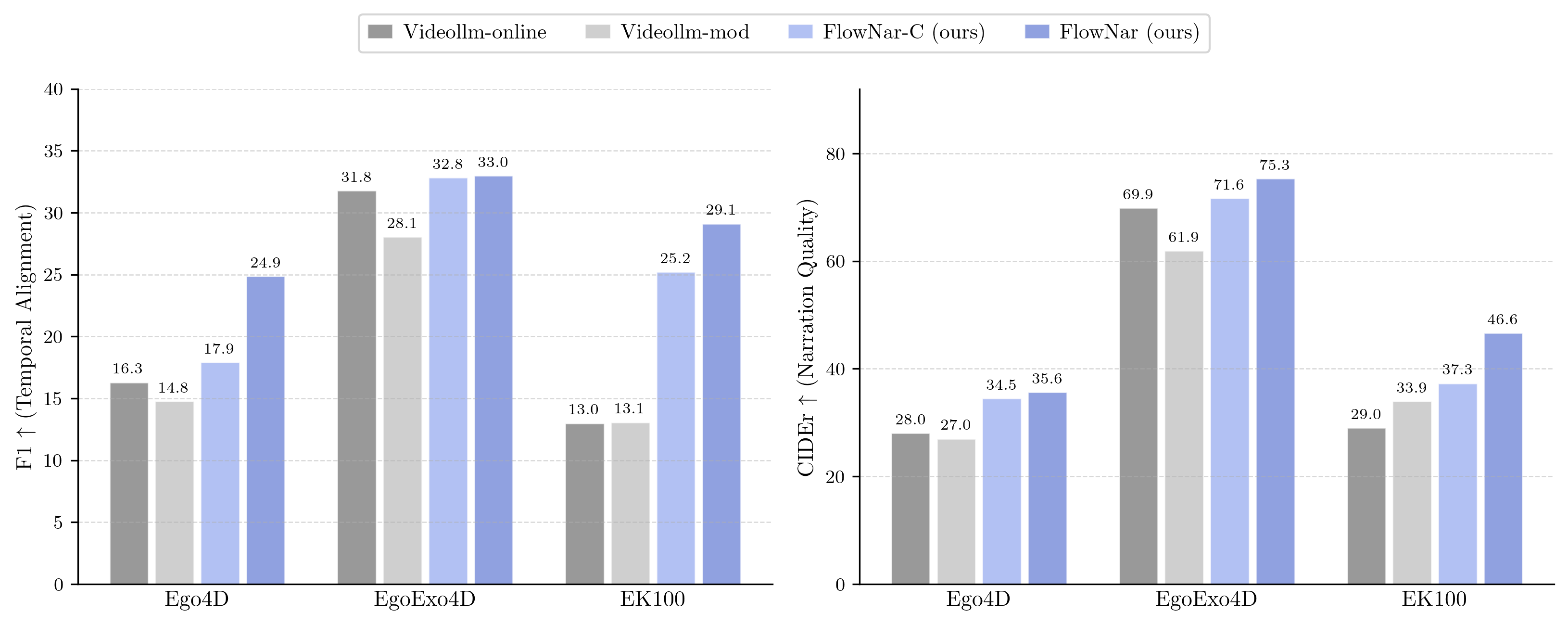
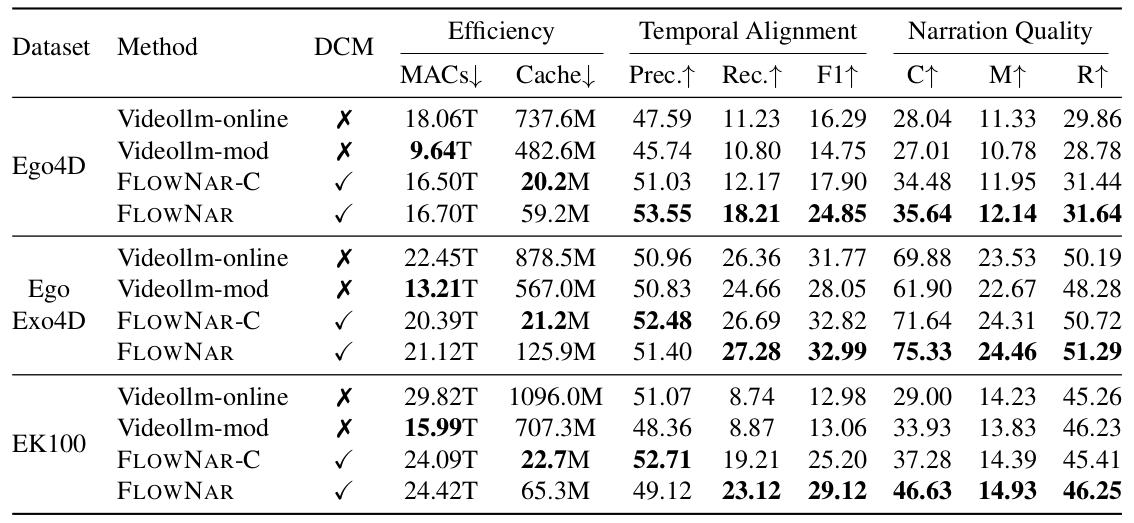
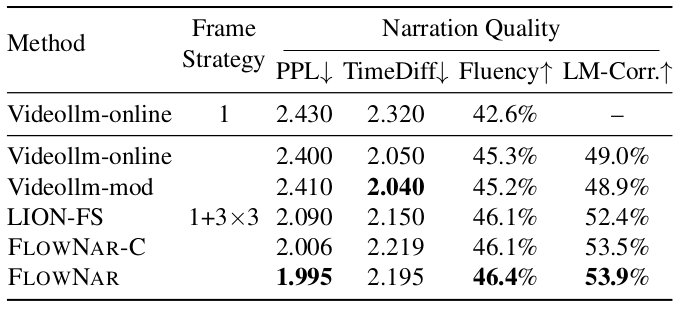
FlowNar: Scalable Streaming Narration
FlowNar: Scalable Streaming Narration
for Long-Form Videos
1Karlsruhe Institute of Technology (KIT)
2Fraunhofer IOSB
3Lamarr Institute
4University of Bonn
†Corresponding author